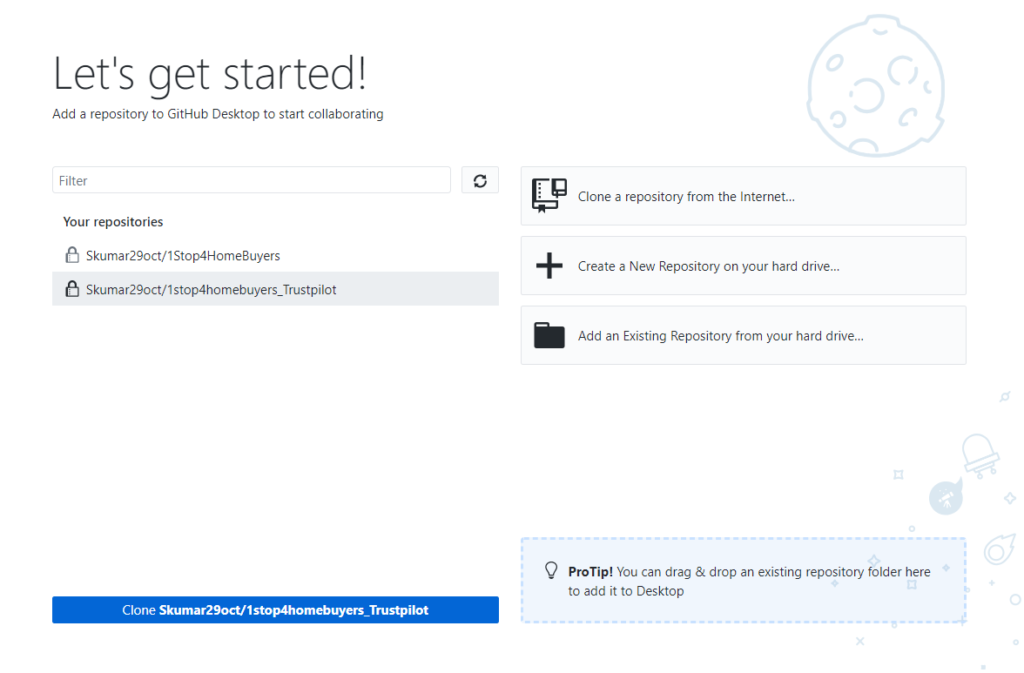
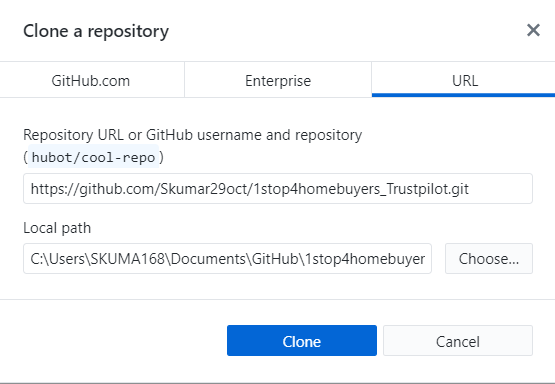
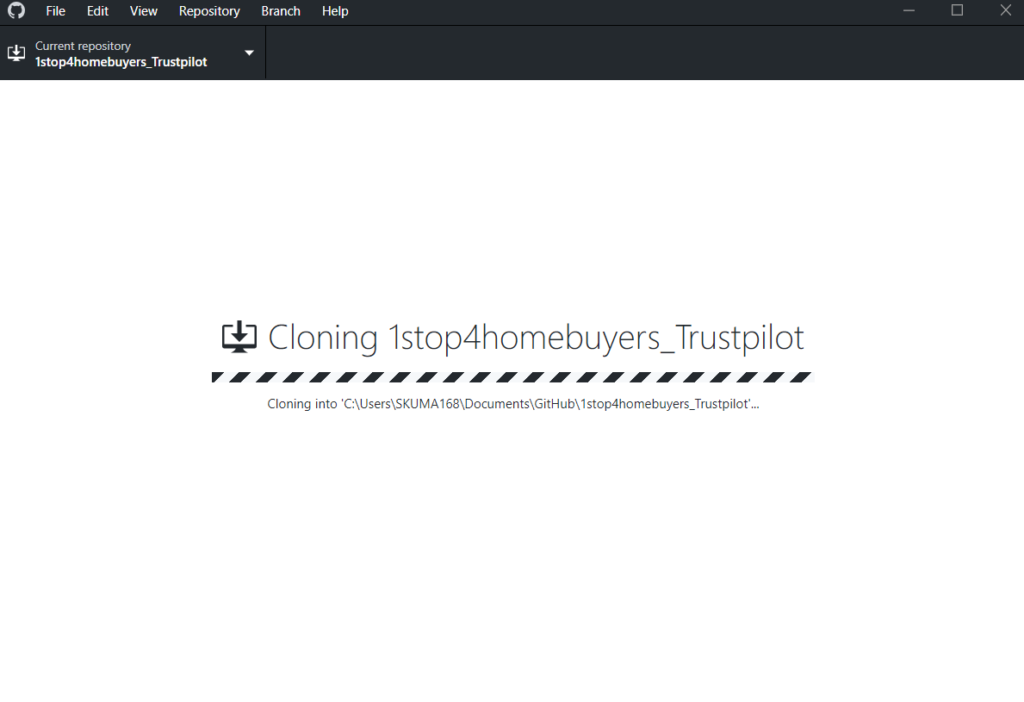
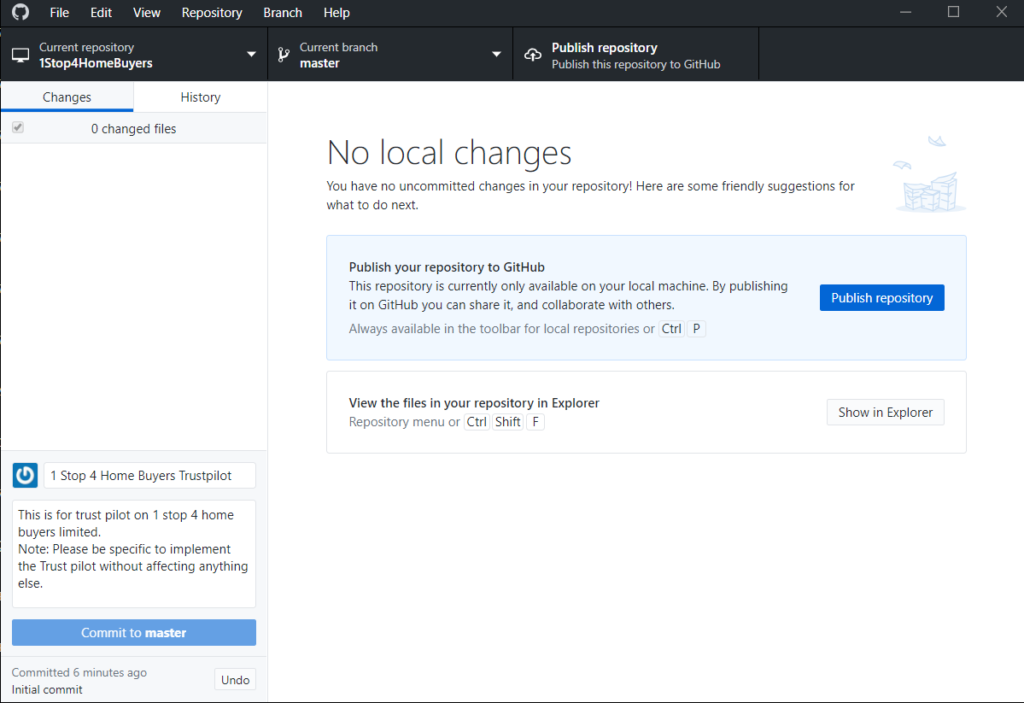
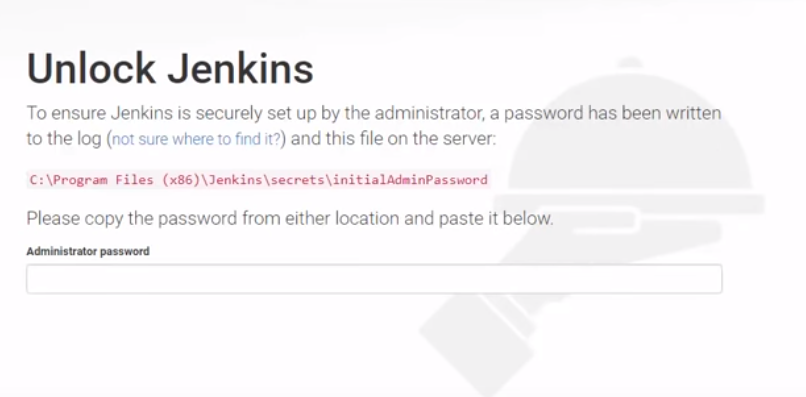
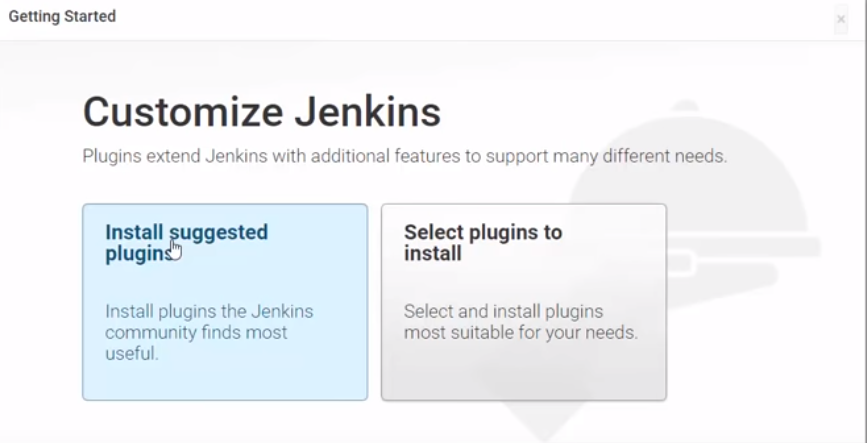
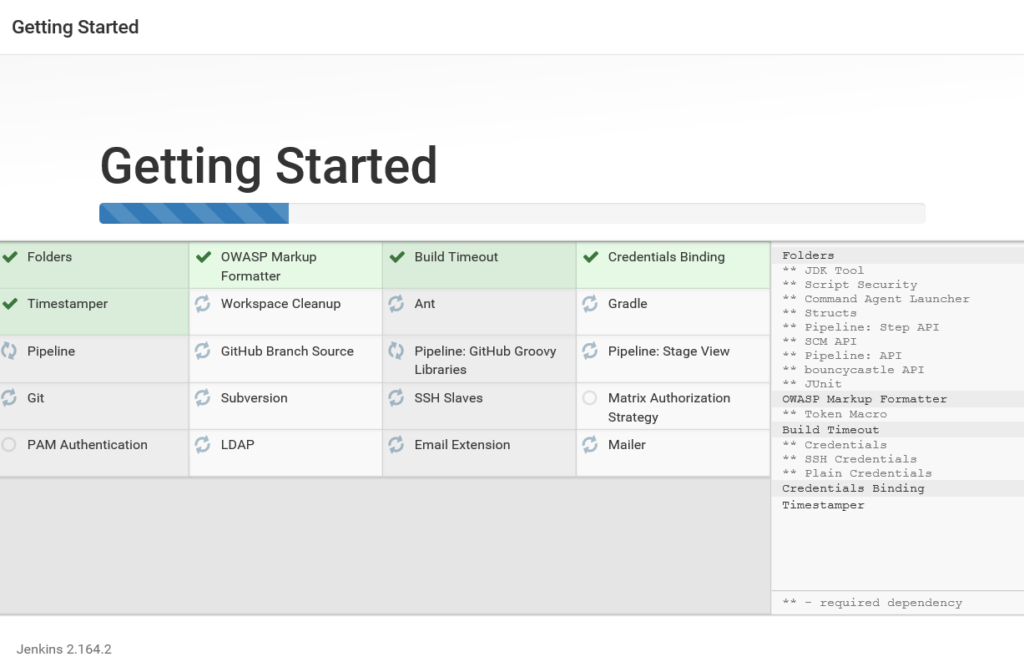
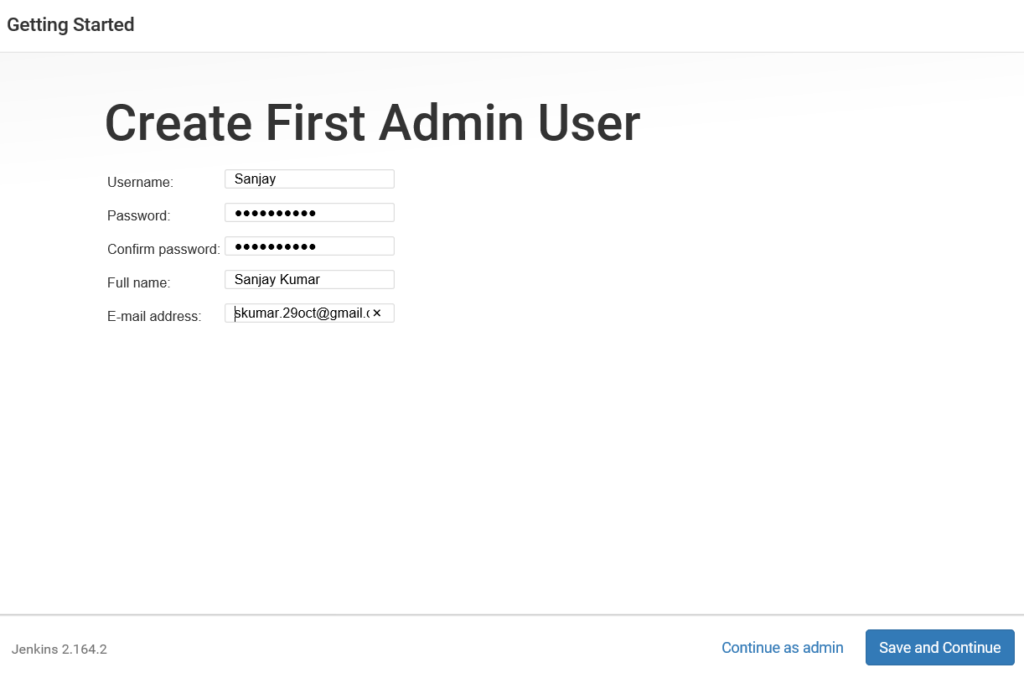
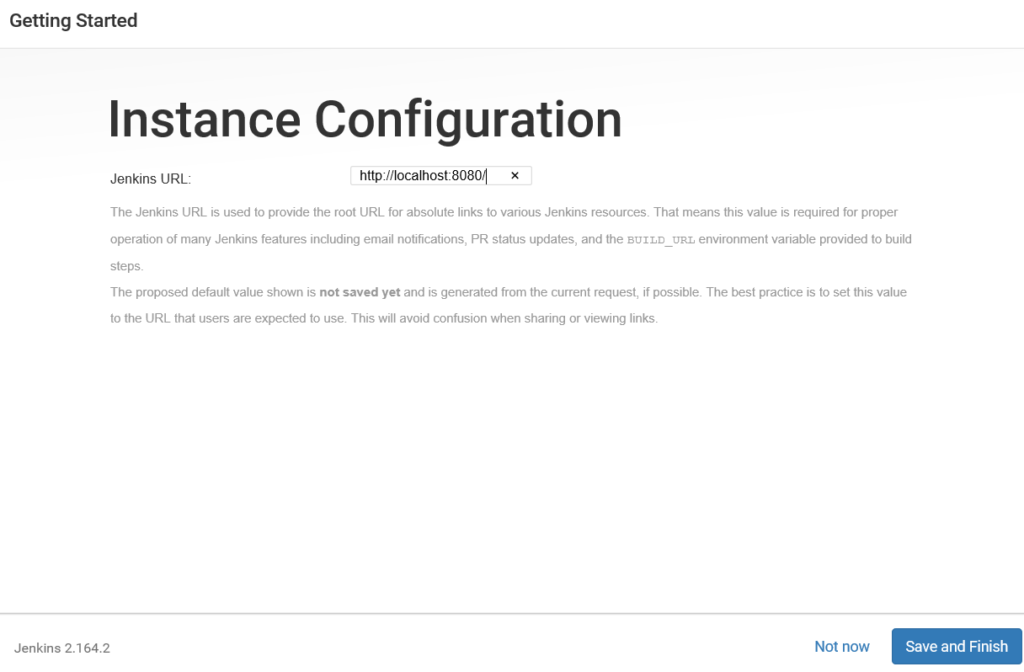
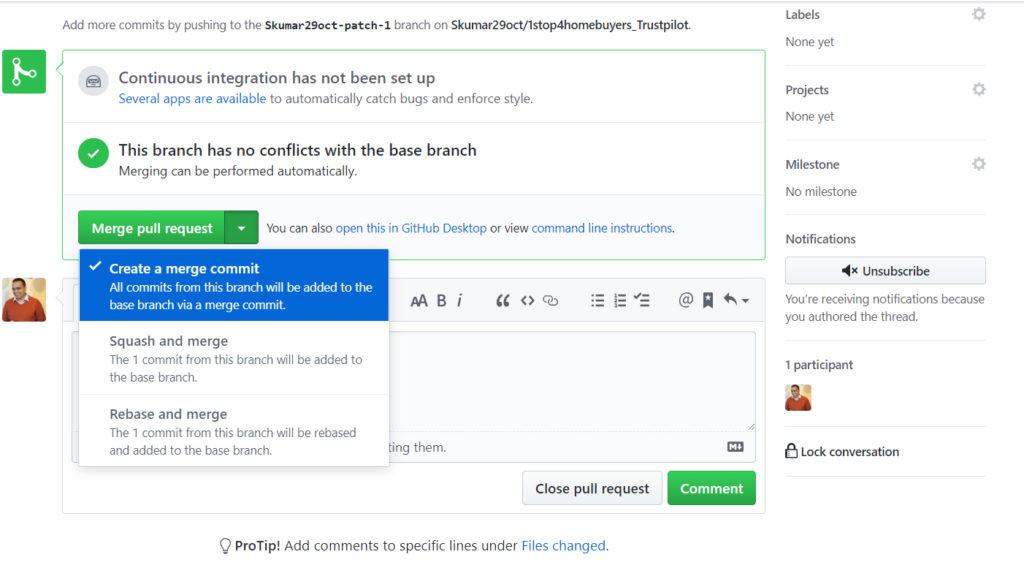
We can run following queries to check all are fine with Standby db.
@Primary
set lines 500
column destination format a35 wrap
column process format a7
column archiver format a8
column ID format 99
select dest_id “ID”,destination,status,target,archiver,schedule,process,mountid from v$archive_dest;
Output (Status should return valid for standby destination)
ID DESTINATION STATUS TARGET ARCHIVER SCHEDULE PROCESS MOUNTID
1 /podaai/arch/PODAAI1/ VALID PRIMARY ARCH ACTIVE ARCH 0
2 podaai1_rmdc VALID STANDBY ARCH ACTIVE ARCH 0
3 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
4 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
5 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
6 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
7 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
8 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
9 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
10 INACTIVE PRIMARY ARCH INACTIVE ARCH 0
column error format a55 tru
select dest_id,status,error from v$archive_dest;
Output (Should not return any error messages)
DEST_ID STATUS ERROR
1 VALID
2 VALID
3 INACTIVE
4 INACTIVE
5 INACTIVE
6 INACTIVE
7 INACTIVE
8 INACTIVE
9 INACTIVE
10 INACTIVE
column message format a80
select message, timestamp from v$dataguard_status where severity in (‘Error’,’Fatal’) order by timestamp;
Output (Should not return any rows)
SCP SYNTAX
scp PGEORI_2_23362*.arc rmohsgeor36.oracleoutsourcing.com:/pgeori/arch/PGEORI1
$ scp PCFITI_1_57371_604994162.arc rmohscfit03.oracleoutsourcing.com:/pcfiti/arch/
PCFITI_1_57371_604994162.arc
@Standby
select process,status,client_process,sequence#,block#,active_agents,known_agents from v$managed_standby;
Output (Should show MRP process up and running)
PROCESS STATUS CLIENT_P SEQUENCE# BLOCK# ACTIVE_AGENTS KNOWN_AGENTS
ARCH CONNECTED ARCH 0 0 0 0
ARCH CONNECTED ARCH 0 0 0 0
ARCH CONNECTED ARCH 0 0 0 0
ARCH CONNECTED ARCH 0 0 0 0
RFS RECEIVING UNKNOWN 13491 36819 0 0
RFS RECEIVING UNKNOWN 13364 1810 0 0
RFS RECEIVING UNKNOWN 13493 38735 0 0
RFS RECEIVING UNKNOWN 13363 156 0 0
RFS ATTACHED UNKNOWN 13494 36989 0 0
RFS RECEIVING UNKNOWN 0 0 0 0
RFS RECEIVING UNKNOWN 13362 327 0 0
PROCESS STATUS CLIENT_P SEQUENCE# BLOCK# ACTIVE_AGENTS KNOWN_AGENTS
RFS ATTACHED UNKNOWN 13365 165 0 0
RFS RECEIVING UNKNOWN 13492 36686 0 0
MRP0 WAIT_FOR_LOG N/A 13493 0 0 0
column message format a80
select message, timestamp from v$dataguard_status where severity in (‘Error’,’Fatal’) order by timestamp;
Output (Should not return any rows)
Note: If we gets results as shown above, we can close the standby alerts as TFALSE.
Pls correct/ add comments if required.
To determine if there is an archive gap on your physical standby database, query
the as shown in the following example:
break on report
compute sum of GAP on report
select to_char(sysdate,’DD.MM.RR HH24:MI:SS’) time, a.thread#, (select
max(sequence#) from v$archived_log where archived’YES’ and thread#a.thread#)
archived, max(a.sequence#) applied, (select max(sequence#) from v$archived_log
where archived’YES’ and thread#a.thread#)-max(a.sequence#) gap from
v$archived_log a where a.applied’YES’ group by a.thread#;
To verify the log application status.
On primary DB
SELECT THREAD#, MAX(SEQUENCE#) AS “LAST_GENERATED_LOG” FROM V$LOG_HISTORY GROUP BY THREAD#;
Standby DB
SELECT THREAD#, MAX(SEQUENCE#) AS “LAST_APPLIED_LOG” FROM V$LOG_HISTORY GROUP BY THREAD#;
To see the max seq applied.
select THREAD#,max(SEQUENCE#) from v$archived_log where APPLIED’YES’ group by THREAD#;
To stop the MRP.
alter database recover managed standby database cancel;
To start the MRP.
recover managed standby database disconnect from session;
To recover standby manually.
SQL> recover automatic standby database;
SQL> recover managed standby database parallel
a. no. of cpu…
b. no. of thread possible on each cpu…
total threads a*b -1
To enable the in one commmand.
SQL> ALTER SYSTEM SET log_archive_dest_state_2enable scopeboth SID’*’ ;
To start the standby and put in MRP
SQL> startup nomount;
SQL> alter database mount standby database;
recover managed standby database disconnect from session ;
To find the missing logs @ standby
./autofs/cmd_ctr/database/missing_seq.sh
missing_seq.sh Parameter missing: missing_seq.sh low_seq high_seq thread#_if_rac
In case of Non Rac: missing_seq.sh 200 220 No need to give thread#
for Non Rac: missing_seq.sh 200 220 3 Here 3 is the thread#
set pagesize 10000
SELECT A., Round(A.Count#B.AVG#/1024/1024) Daily_Avg_Mb
FROM
(
SELECT thread#,
To_Char(First_Time,’YYYY-MM-DD’) DAY,
Count(1) Count#,
Min(RECID) Min#,
Max(RECID) Max#
FROM
gv$log_history
GROUP BY
thread#, To_Char(First_Time,’YYYY-MM-DD’)
ORDER
BY 2 DESC
) A,
(
SELECT Thread#,
Avg(BYTES) AVG#,
Count(1) Count#,
Max(BYTES) Max_Bytes,
Min(BYTES) Min_Bytes
FROM
gv$log group by thread#
) B where a.thread#b.thread#;
THREAD# DAY COUNT# MIN# MAX# DAILY_AVG_MB
1 2010-03-24 113 133452 133564 14238
1 2010-03-23 174 133278 133451 21924
1 2010-03-22 182 133096 133277 22932
1 2010-03-21 112 132984 133095 14112
1 2010-03-20 145 132839 132983 18270
1 2010-03-19 176 132663 132838 22176
1 2010-03-18 200 132463 132662 25200
1 2010-03-17 154 132309 132462 19404
1 2010-03-16 164 132145 132308 20664
1 2010-03-15 40 132105 132144 5040